Attention 机制在近几年来大火,在自然语言处理,信号处理,计算机视觉等领域取得了很大的进展。本文关注于计算机视觉领域,讲述 Attention 机制的原理,并以医学图像分析领域为依托,介绍了Attention机制的应用。
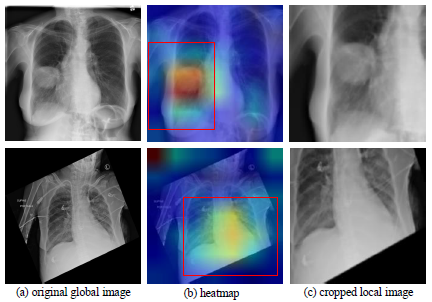
在胸部 X 光诊断中,医生通常先整体看片子中是否有问题,然后再集中精力看有病理可能的局部区域,最后再结合整张片观察,确定病理结论。
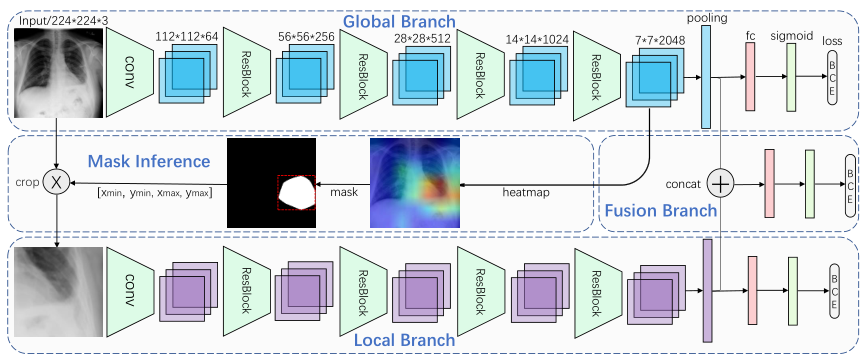
有两个主要分支, global and local branches,以及 a fusion branch,都是分类网络,可预测图像中是否存在病理。 给定一个图像,首先使用全局图像根据分类CNN对 global branch 进行微调。 然后,我们从全局图像中裁剪出一个 attended region,并对其进行训练以在 local branch 上进行分类。 最后,将 global branch 和 local branch 支的最后一个池化层连接起来,以对 fusion branch 进行微调。
思路很清晰,接下来重点分析做 attention 的:
$f_g^k(x,y)$ 表示最后一层卷积的第 $k$ 个 channel,$g$ 表示是 global branch. 首先,对 $f_g^k(x,y)$ 取绝对值。然后,通过计算 channels 上的最大值得到 attention heat map $H_g$.
$H_g$ 的值表示了 activations 的重要性。
上面的叫做可以称之为 hard attention,权重要么是 0,要么是 1. 下面介绍几个 soft attention.
Squeeze-And-Excitation-Networks
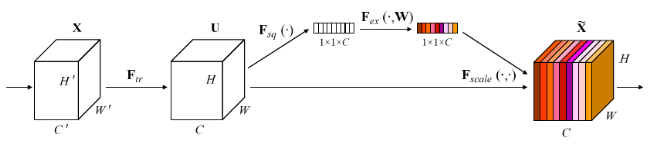
对于任何从 $\textbf{X}$ 到 $\textbf{U}$ 的变换 $\textbf{F}_{tr}$, 存在一个变换 $\textbf{F}_{sq}$ 压缩全局特征,随后有一个 excitation 操作 $\textbf{F}_{ex}$ , 这是一个 self-gating 的操作,构建了一个 channel-wise 权重响应,并与 $\textbf{F}_{tr}$ 的输出进行 channel-wise 相乘。
Squeeze 操作的数学描述:
其实就是全局平均池化(global average pooling)。Excitation 操作描述如下:
包括 2 个卷积,$W_1$ 降低 channel 的数量,$W_2$ 再升回去。最后再与 $\textbf{F}_{tr}$ 的输出相乘,可以看做是一种 self-attention.
Stand-Alone Self-Attention
卷积是现代计算机视觉系统的基本单元。最近的方法主张 going beyond convolutions 以捕获 long-range dependencies。这些工作着重于 content-based interactions( 例如 self-attention 和 non-local means )增强卷积模型。随之而来的自然问题是,attention 是否可以作为视觉模型的 stand-alone primitive,而不是仅仅作为卷积之上的增强。在开发和测试 pure self-attention视觉模型时,作者验证了self-attention 确实可以是有效的独立层。使用应用于 ResNet 模型的一种形式的 self-attentional 替换 spatial convolutions 的所有实例的简单过程将产生一个 fully self-attentional 的模型,该模型在 ImageNet 分类表现出色,FLOPS减少了12%,参数减少了29%。在COCO对象检测中,pure self-attention 模型与 RetinaNe t的 mAP 相匹配,而FLOPS减少了39%,参数减少了34%。详细的 ablation 研究表明,self-attention 在后面的层中使用时尤其有影响。这些结果表明,stand-alone self-attention 是视觉从业者工具箱的重要补充。
CNN 发展迅速,但是捕获 long range interactions 仍然具有挑战性。最近,attention 机制被广泛应用,以解决这个问题,如基于 channel-based attention 机制的 Squeeze-Excite,以及基于 spatially-aware attention 机制的 Non-local. 这些工作使用 global attention layers 作为现有网络的 add-on. 这些全局形式涉及输入的所有空间位置,将其使用限制在通常需要对原始图像进行大量降采样的small inputs 中。
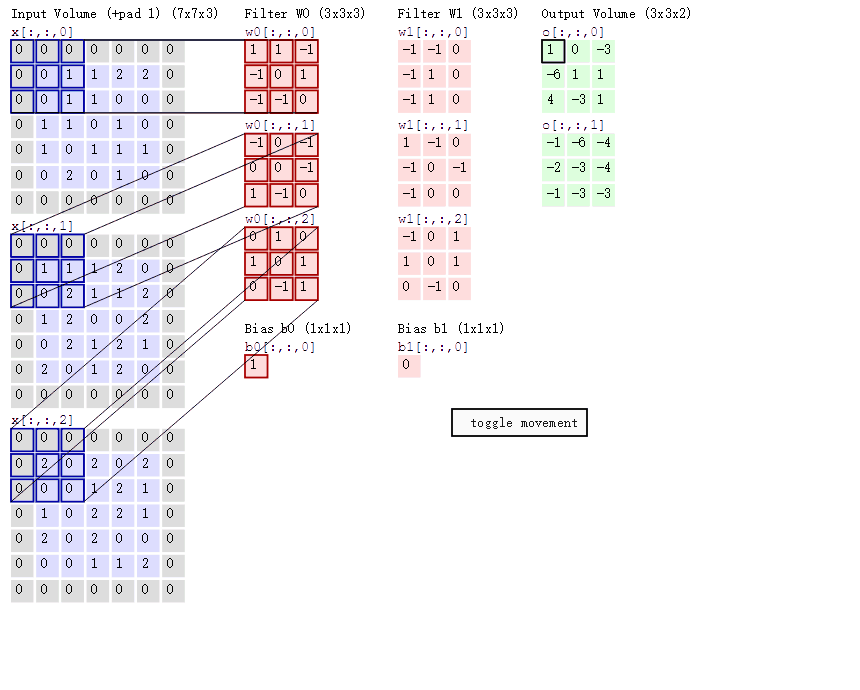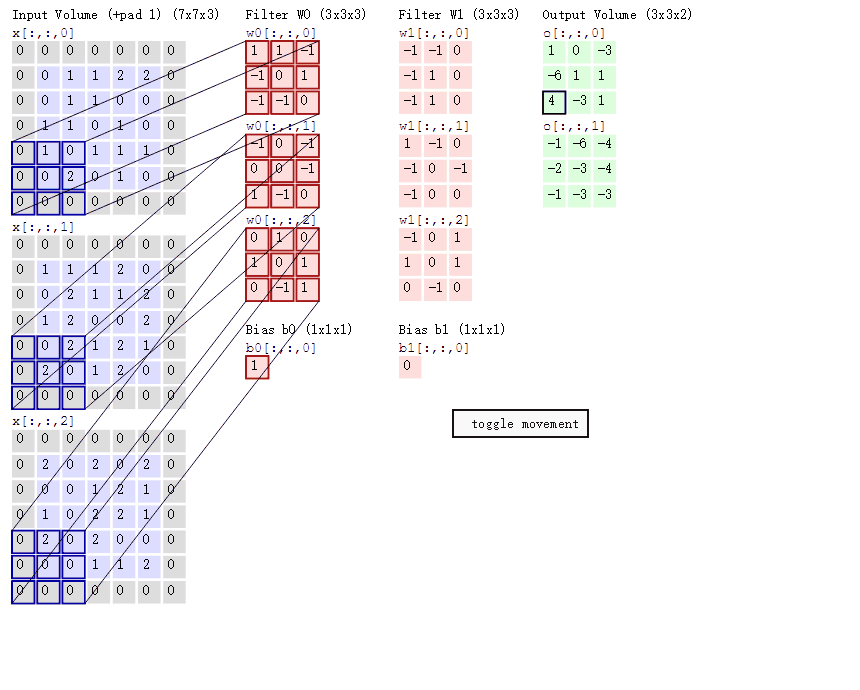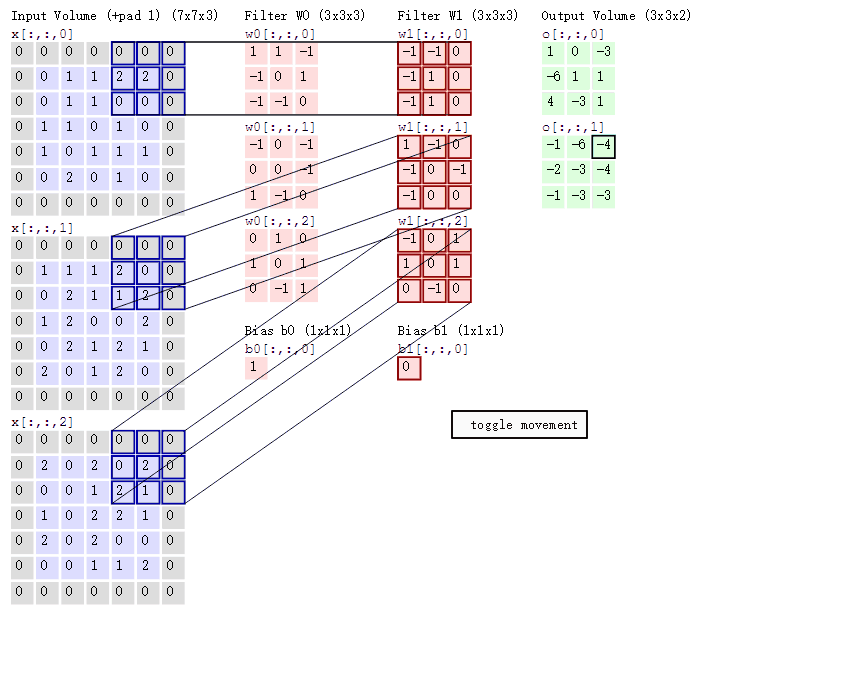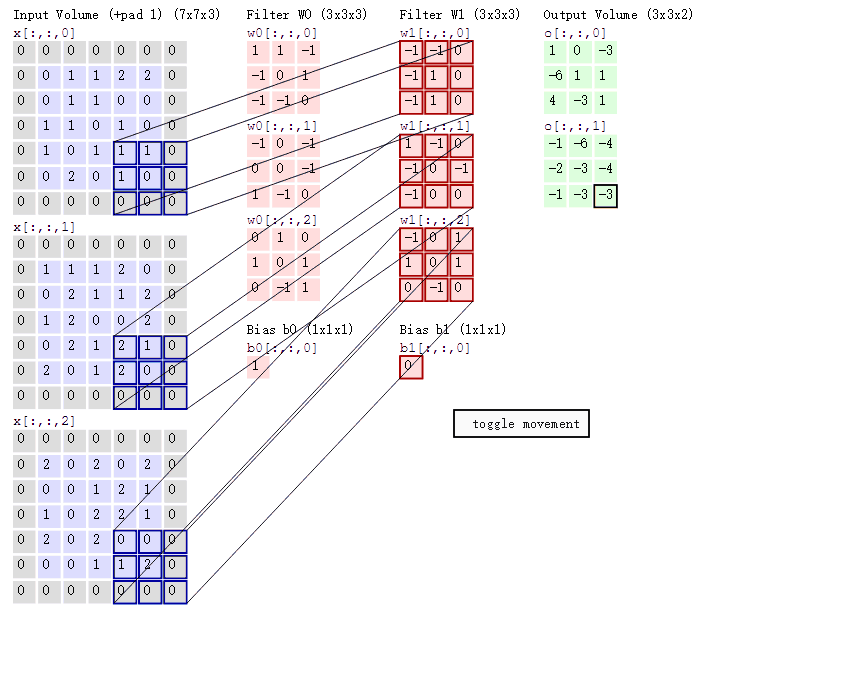
上图来自这个博客. 很详细的展示了卷积过程。
正常的一个卷积:
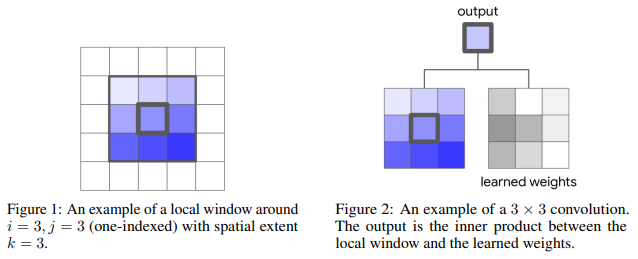
未完待续……
参考资料:
[1] Guan, Qingji, et al. “Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification.” arXiv preprint arXiv:1801.09927 (2018). https://arxiv.org/abs/1801.09927
[2] https://blog.csdn.net/cskywit/article/details/79569788
[3] J. Hu, L. Shen, and G. Sun, “Squeeze-and-Excitation Networks,” in CVPR 2018: Computer Vision and Pattern Recognition, 2018, pp. 7132–7141.
[4] Ramachandran, Prajit, et al. “Stand-Alone Self-Attention in Vision Models.” arXiv preprint arXiv:1906.05909 (2019).
[5] Self-Attention In Computer Vision - towards data science

