计算机视觉领域关于自注意力机制的一篇重要文章。
CNN和 RNN 每次计算只能处理一个 local neighborhood,Non-local Neural Networks 提出了 non-local operations 的想法,以捕获 long-range dependencies. Non-local operation 在计算某个位置的 response 时,考虑所有位置,并进行加和权重。次方法解决了解決即使相距很远的的 blocks,仍然有可能是彼此有关系的。
1. Introduction
CNN和 RNN 每次计算只能处理一个 local neighborhood, 想要捕捉 long-range dependencies,必须使用很深的网络,造成:
- 计算不够高效
- 难以优化
- non-local 特征讯息传递不灵活
 |
|---|
| Figure 1. A spacetime non-local operation in our network trained for video classification in Kinetics. A position $x_i$’s response is computed by the weighted average of the features of all positions $x_j$ (only the highest weighted ones are shown here). In this example computed by our model, note how it relates the ball in the first frame to the ball in the last two frames. More examples are in Figure 3. |
如上图所示,本文提出了 non-local operations ,一个 non-local 的值 $x_i $ 来自作为输入 input feature maps 中所有位置 $x_j $ 的加权和。
使用 non-local operations 的几个优点:
- 通过计算任意两个位置间的interactions,non-local operations 可以直接捕获其 long-range dependencies,无关它们之间的距离。
- 非常高效,即使只有几层也能取得很好的效果。
- non-local operations 保持了输入大小,可以很容易地结合到其它网络中。
2. Related Work
Non-local image processing. 来源于 Non-local means。
Graphical models. 可以通过图模型,如CRF,来捕获 long-range dependencies,CRF可以作为后处理步骤,也可以融合到RNN中。但是本文的方法更加简单,也与图神经网络有关系。
Feedforward modeling for sequences. Recently there emerged a trend of using feedforward (i.e., non-recurrent) networks for modeling sequences in speech and language. In these methods, long-term dependencies are captured by the large receptive fields contributed by very deep 1-D convolutions. These feedforward models are amenable to parallelized implementations and can be more
efficient than widely used recurrent models.
Self-attention. 本文方法与 self-attention 方法有关,self-attention 模块通过考虑所有位置并在 embedding space 中获取它们的加权平均值,来计算序列(例如句子)中某个位置的响应。作者在后面有讨论, self-attention 可以视为某种形式的 non-local mean, 从这角度来说,将机器翻译中的 self-attention 机制扩展到 CV 领域。
Interaction networks.
Video classification architectures.
3. Non-local Neural Networks
3.1. Formulation
通过非局部平均,作者定义了如下的 non-local operation:
其中,
- $i$:输出位置的 index(in space, time, or spacetime)
- $j$:所有 enumerates 出来可能位置的 index
- $\textbf x$: 输入(image, sequence, video; often their features)
- $\textbf y$: 输出,大小和 $\textbf x$ 相同
- $f$:计算 $i$ 和所有 $j$ 之间的 affinity
- $g$:计算位置 $j$ 处的输入信号表示,a representation of the input signal at the position $j$
- $\mathcal C$:normalizer
可以清楚看出 non-local 的特性,考虑了所有的位置 $\forall j$. 相比 CNN 操作只关心邻域和 RNN 只关心前一个时间点。此外,non-local operation 和 fully-connected 相比有许多优点:
| non-local operation | fc |
|---|---|
| 考虑不同位置的关系 | 单纯学习权重 |
| 支持不同的 input size | 固定大小 |
| 容易融合到各种网络中 | 只能接在网络最后面 |
3.2. Instantiations
接下来,描述不同版本的 $f$ 和 $g$,作者发现,这些选择不太影响 models,表示了:non-local 想法才是改善的主因。
为了方便描述,我们只考虑 $g$ 是一个 linear embedding:$g(\textbf x_j) = W_g \textbf x_j$,其中 $W_g$ 是一个 weight matrix,下面介绍不同的 $f$(基本上,就是找出位置 $i$ 和所有位置 $j$ 的关系),和他们对应的 normalizer $\mathcal C$。
Gaussian
其中:
- $\textbf x_i^T \textbf x_j$: 点积相似度(欧式距离也 ok,但点积较好实作)
- $\mathcal C(\textbf x) = \sum_{\forall j} f(\textbf x_i, \textbf x_j)$
Embedded Gaussian
其中:
- $\theta(\textbf x_i) = W_\theta \textbf x_i$
- $\phi(\textbf x_j) = W_\phi \textbf x_j$
- $\mathcal C(\textbf x) = \sum_{\forall j} f(\textbf x_i, \textbf x_j)$
作者指出,self-attention module 是这个版本的 non-local operations 的一个特例。可以观察到,给定一个 $i$, $\frac{1}{\mathcal C(x)} f(\textbf x_i, \textbf x_j)$ 是透过维度 $j$ 的 softmax. 所以,我们有 $\textbf y =softmax(\textbf x^T W_{\theta}^T W_{\phi} \textbf x)g(\textbf x) $。
Dot product
其中:
- $\theta(\textbf x_i) = W_\theta \textbf x_i$
- $\phi(\textbf x_j) = W_\phi \textbf x_j$
- $\mathcal C(\textbf x) = N$
Concatenation
其中:
- $[\cdot, \cdot]$: concatenation\
- $\textbf w_f$: 将 concatenated vector 投射成 scalar 的 weight vector
- $\mathcal C(\textbf x) = N$:
- 在这里 $f$ 多采用了一个 ReLU
3.3. Non-local Block
我们将式 (1) 中的 non-local operation 包装到 non-local block 中,该 block 可以合并到许多现有体系的架构中,non-local block 定义如下:
应用了残差结构,可以在任何事先训练好的 model 插入一个 non-local block。
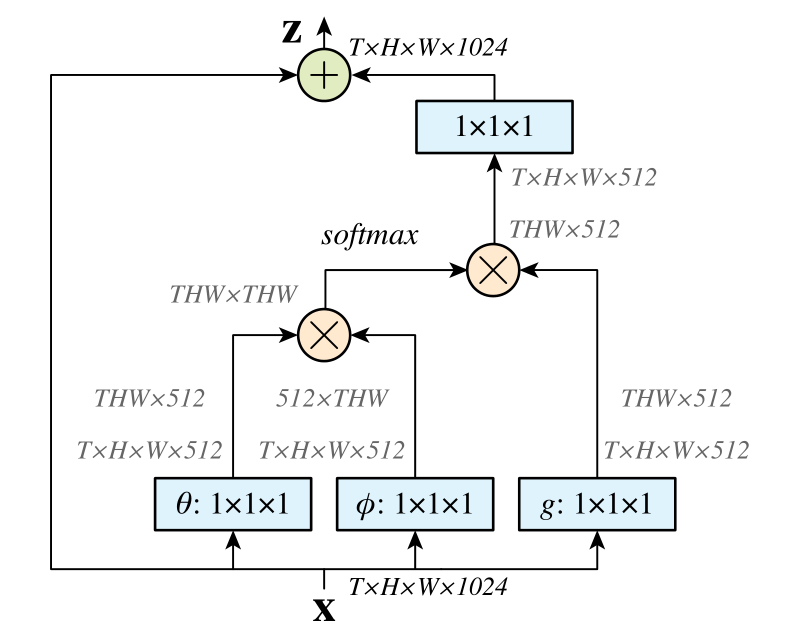 |
|---|
| Figure 2. A spacetime non-local block. The feature maps are shown as the shape of their tensors, e.g., $T \times H \times W \times 1024$ for $1024$ channels (proper reshaping is performed when noted). “$\otimes$” denotes matrix multiplication, and “$\oplus$” denotes element-wise sum. The softmax operation is performed on each row. The blue boxes denote $1 \times 1 \times 1$ convolutions. Here we show the embedded Gaussian version, with a bottleneck of $512$ channels. The vanilla Gaussian version can be done by removing $\theta$ and $\phi$, and the dot-product version can be done by replacing softmax with scaling by $1 / N$. |
博客 画了一个示意图:

4. 代码实现
参考:https://github.com/AlexHex7/Non-local_pytorch
基于PyTorch
Gaussian
1 | class _NonLocalBlockND(nn.Module): |
Embedded Gaussian
1 | class _NonLocalBlockND(nn.Module): |
Dot product
1 | class _NonLocalBlockND(nn.Module): |
Concatenation
1 | class _NonLocalBlockND(nn.Module): |
参考资料:

