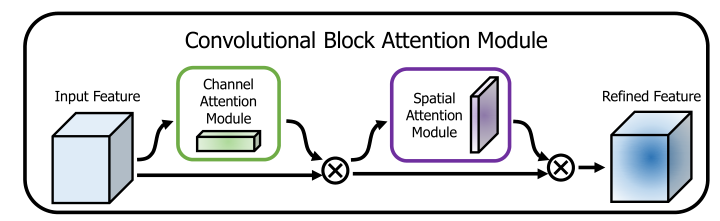
给定一个中间的 feature map, 可以从channel 和 spatial 2 个维度推理 attention maps,然后,这些 attention maps 通过相乘以自适应地进行特征增强。
ECCV2018的一篇文章:
Attention 不仅可以告诉我们关注的重点,还可以改善感兴趣的表示方式。
本文的目标就是通过 attention mechanism 提高 representation power: 专注于有用的信息,抑制无用的信息。文本不仅关注 cross-channel,还关注 spatial information, 因此,作者顺序地执行 channel 和spatial attention modules,每个 branch 都可以分别学习 ‘what’ and ‘where’ to attend in the channel and spatial axes.
We visualize trained models using the grad-CAM and observe that CBAM-enhanced networks focus on target objects more properly than their baseline networks. 因此,作者推测性能的提升来自准确的 attention和噪声的降低。作者还精心地设计地轻量化,在大部分情况下计算量和参数的负担都是可以接受的。
对于一个 feature map $\textbf F \in \R^{C\times H\times W}$, CBAM 顺序地 infers 一个1D 的 channel attention map $\textbf M_{c} \in \R^{C\times 1 \times 1}$ 和一个 2D 的 spatial attention map $\textbf M_{s} \in \R^{1\times H \times W}$
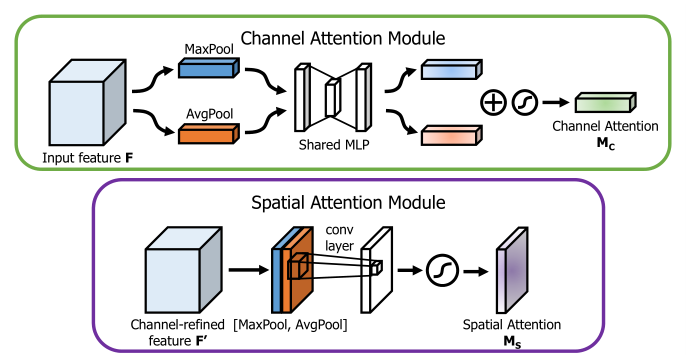
Channel attention: 与 SENet 类似,多并了一个max-pooling,作者说,We empirically confirmed that exploiting both features greatly improves representation power of networks rather than using each independently.
Channel attention: 对 channel 维度进行max-pooling 和 average-pooling,然后并起来,再经过一个卷积,得到 spatial attention map.
==作者尝试了并行和串行,还调整了顺序,实验发现先 channel 再 spatial 的串行模式比较好。==
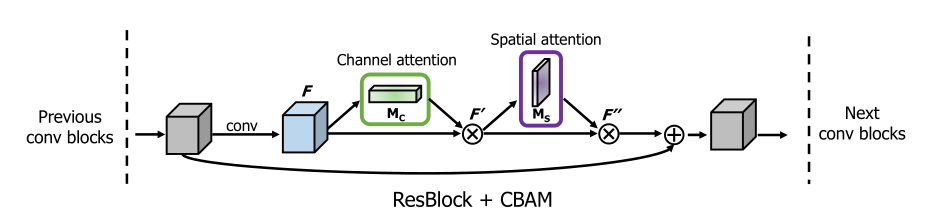
Network Visualization with Grad-CAM

代码分析:
1 | class ChannelAttention(nn.Module): |

