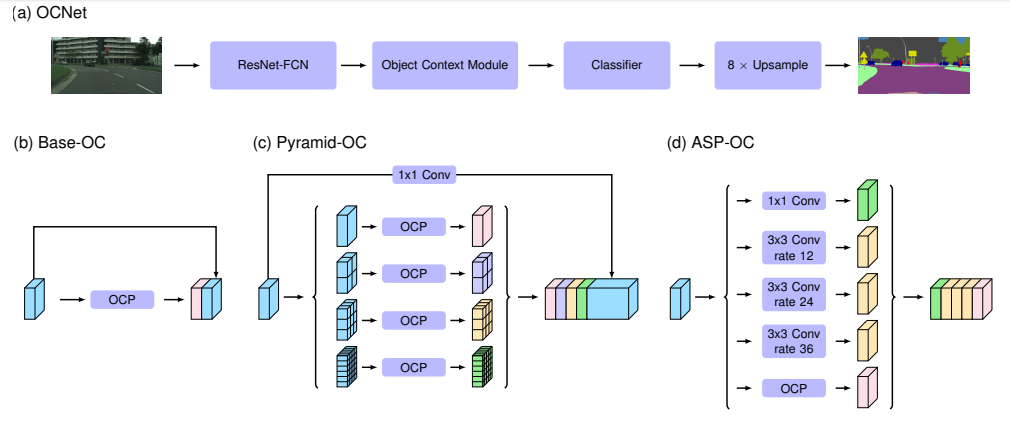
将object context (spatial attention) 和卷积强强联合,分别捕捉全局和局部信息,并在多个数据集上取得很高的精度。
PSPNet 和 ASPP 等网络的 patial context 是可能属于不同类别的像素的混合,稳定性不够好。
作者为每个像素提出一个 object context,是与它同类的像素点的集合。作者提出了一个新的 object context pooling (OCP),aggregate the information according to the object context. 对每个 像素 $p$ 计算一个 similarity map,其中每个 similarity score 指示了相应的像素和 $p$ 属于同一类的 degree.
作者利用 object context 来更新每个像素的表示,object context pooling 的实现来源于 self-attention approach。
语义分割有 2 大挑战:
- resolution
- multi-scale
object context pooling 包括 2 个重要的步骤:
Object context estimation. 计算一个 object context map,$\textbf w_p$, 表示每个像素与 $p$ 属于同一类的自由度。
$f_q(\cdot)$ 和 $f_k(\cdot)$ 分别表示 query 和 key.
Object context aggregation.
$\phi (\cdot)$ is the value transform function following thes elf-attention.

