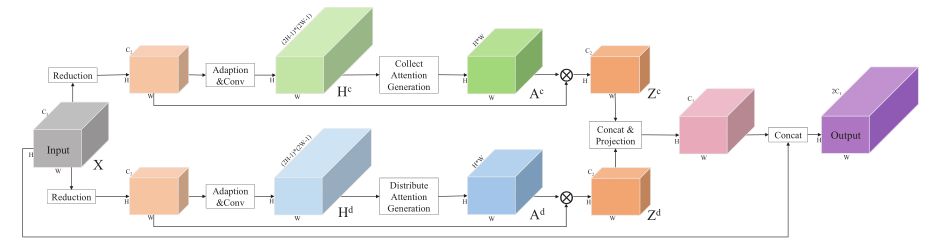
作者认为CNN中信息流被约束在 local neighborhood regions,限制了复杂场景的理解。因此提出了 point-wise spatial attention network (PSANet) 来缓和这种 local neighborhood constraint。通过 self-adaptively learned attention mask,将feature map 中的每个位置与其余位置联系起来。此外,还能够进行双向信息传播以进行 scene parsing。可以收集其他位置的信息以帮助预测当前位置,反之亦然,可以分发当前位置的信息以辅助预测其他位置。
ECCV2018的文章:
通过 PSA 学习到的 masks 是自适应的,对位置和类别信息很敏感。
为了捕获 contextual information,尤其是 long range 的, information aggregation对于场景解析非常重要,如Parsenet,Deeplab,PSPNet,Reseg等网络结构。在本文中,作者将 information aggregation 视为一种 information flow,并提出对每个 position 自适应地学习 pixel-wise global attention map,才能够 2 个角度 aggregate contextual information.
- $\textbf z_i$: the newly aggregated feature at position $i$.
- $\textbf x_i$: featurer epresentation at position $i$ in the input feature map.
- $\forall j \in \Omega {i}$: enumeratesa all positions in the region of interest associated with $i$.
- $\Delta_{ij}$: relative location of position $i$ and $j$.
- $F(\textbf x_i,\textbf x_j,\Delta_{ij})$: any function or learnedp arameters according to the operation and it represents the information flow from $j$ to $i$.
因为考虑了相对位置 $\Delta_{ij}$,$F(\textbf x_i,\textbf x_j,\Delta_{ij})$ 对不用的相对位置是敏感的。可以简化之:
- $\{F_{\Delta_{ij}}\}$: a set of position-specific functions.
建模了从位置 $j$ 到位置 $i$ 的信息流。$F_{\Delta_{ij}}(\cdot,\cdot)$ 的输入包括 source and target information. 当 feature maps中有许多 position 时,组合 $(\textbf x_i,\textbf x_j)$ 是非常 large 的,因此,作者简化并做了近似。
首先,simplify $F_{\Delta_{ij}}(\cdot,\cdot)$ as
公式(2)可重写为
也可以这样简化:
最终可以简化为 bi-direction information propagation path
最终,we model this bi-direction information propagation as

Specifically, our PSA module, aiming to adaptively predict the information flow over the entire feature map, takes all the positions in feature map as $\Omega(i)$ and utilizes the convolutional layer as the operation of $F_{\Delta_{ij}}(\textbf x_i)$ and $F_{\Delta_{ij}}(\textbf x_j)$. Both $F_{\Delta_{ij}}(\textbf x_i)$ and $F_{\Delta_{ij}}(\textbf x_j)$ can then be regarded as predicted attention values
to aggregate feature $\textbf x_j$. We further rewrite Eq. (7) as
where $\textbf a^c_{i,j}$ and $\textbf a^d_{i,j}$ denote the predicted attention values in the point-wise attention maps $\textbf A^c$ and $\textbf A^d$ from ‘collect’ and ‘distribute’ branches, respectively.

